
Содержание статьи
Что такое машинное обучение?
Машинное обучение представляет собой науку (и искусство) программирования компьютеров для того, чтобы они могли обучаться на основе данных.
Вот более общее определение.
Машинное обучение — это научная дисциплина, которая наделяет компьютеры способностью учиться, не будучи явно запрограммированными.
Артур Самуэль, 1959 год
А ниже приведено определение, больше ориентированное на разработку.
Говорят, что компьютерная программа обучается на основе опыта Е по отношению к некоторой задаче Т и некоторой оценке производительности Р, если ее производительность на Т, измеренная посредством Р, улучшается с опытом Е.
Том Митчелл, 1997 год
Скажем, ваш фильтр спама является программой МО, которая способна научиться отмечать спам на заданных примерах спам-сообщений (возможно, маркированных пользователями) и примерах нормальных почтовых сообщений (не спама). Примеры, которые система использует для обучения, называются обучающим набором (training set).
Каждый обучающий пример называется обучающим образцом (training instance или training sample). В рассматриваемой ситуации задача Т представляет собой отметку спама для новых сообщений, опыт Е — обучающие данные (training data), а оценка производительности Р нуждается в определении: например, вы можете применять коэффициент корректно классифицированных почтовых сообщений.
Эта конкретная оценка производительности называется точностью (accuracy) и часто используется в задачах классификации. Если вы просто загрузите копию Википедии, то ваш компьютер будет содержать намного больше данных, но не станет внезапно выполнять лучше какую-нибудь задачу. Таким образом, это не машинное обучение.
Для чего используют машинное обучение?
Обдумайте, как бы вы писали фильтр спама с применением приемов традиционного программирования.
- Сначала вы бы посмотрели, каким образом обычно выглядит спам. Вы могли бы заметить, что в теме сообщения в большом количестве встречаются определенные слова или фразы. Возможно, вы также обратили бы внимание на несколько других паттернов (шаблонов) в имени отправителя, теле сообщения и т.д.
- Вы написали бы алгоритм обнаружения для каждого замеченного паттерна, и программа маркировала бы сообщения как спам в случае выявления некоторого числа таких паттернов.
- Вы бы протестировали программу и повторяли шаги 1 и 2 до тех пор, пока она не стала достаточно хорошей. Поскольку задача нетривиальна, в вашей программе с высокой вероятностью появится длинный список сложных правил, который довольно трудно сопровождать.

Рисунок «Традиционный подход»
В противоположность этому подходу фильтр спама, основанный на приемах МО, автоматически узнает, какие слова и фразы являются хорошими прогнозаторами спама, обнаруживая необычно часто встречающиеся шаблоны слов в примерах спам-сообщений по сравнению с примерами нормальных сообщений. Программа оказывается гораздо более короткой, легкой в сопровождении и, скорее всего, более точной.
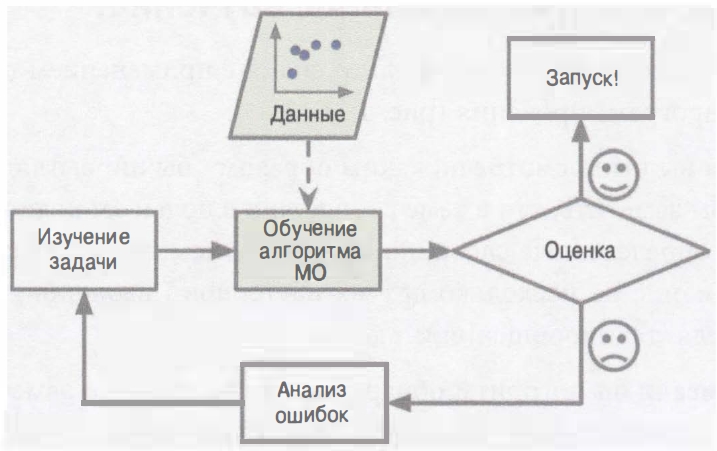
Рисунок «Подход с машинным обучением»
Кроме того, если спамеры обнаружат, что все их сообщения, которые содержат, к примеру, «4U’: блокируются, тогда они могут взамен писать «For U’: Фильтр спама, построенный с использованием приемов традиционного программирования, понадобится обновить, чтобы он маркировал сообщения с «For U». Если спамеры продолжат обходить ваш фильтр спама, то вам придется постоянно писать новые правила. Напротив, фильтр спама, основанный на приемах МО, автоматически заметит, что фраза «For U» стала необычно часто встречаться в сообщениях, маркированных пользователями как спам, и начнет маркировать их без вмешательства с вашей стороны. Еще одна область, где МО показывает блестящие результаты, охватывает задачи, которые либо слишком сложно решать с помощью традиционных подходов, либо для их решения нет известных алгоритмов. Например, возьмем распознавание речи: предположим, что вы хотите начать с простого и написать программу, способную различать слова «один» и «два’: Вы можете обратить внимание, что слово «два» начинается с высокого звука («Д»), а потому жестко закодировать алгоритм, который измеряет интенсивность высокого звука и применяет это для проведения различий между упомянутыми словами.

Рисунок «Автоматическая адаптация к изменениям»
Очевидно, такой прием не будет масштабироваться на тысячи слов, произносимых миллионами очень разных людей в шумных окружениях и на десятках языков. Лучшее решение (во всяком случае, на сегодняшний день) предусматривает написание алгоритма, который учится самостоятельно, имея много звукозаписей с примерами произношения каждого слова. Наконец, машинное обучение способно помочь учиться людям: алгоритмы МО можно инспектировать с целью выяснения, чему они научились (хотя для некоторых алгоритмов это может быть непросто). Например, после того, как фильтр спама был обучен на достаточном объеме спам-сообщений, его легко обследовать для выявления списка слов и словосочетаний, которые он считает лучшими прогнозаторами спама. Временами удастся найти неожиданные взаимосвязи или новые тенденции, приводя к лучшему пониманию задачи. Применение приемов МО для исследования крупных объемов данных может помочь в обнаружении паттернов, которые не были замечены сразу. Это называется интеллектуальным или глубинным анализом данных (data mining). Подводя итоги, машинное обучение замечательно подходит для:
- задач, существующие решения которых требуют большого объема ручной настройки или длинных списков правил — один алгоритм МО часто способен упростить код и выполняться лучше;
- сложных задач, для которых традиционный подход вообще не предлагает хороших решений — лучшие приемы МО могут найти решение;
- изменяющихся сред — система МО способна адаптироваться к новым данным;
- получения сведений о сложных задачах и крупных объемах данных.
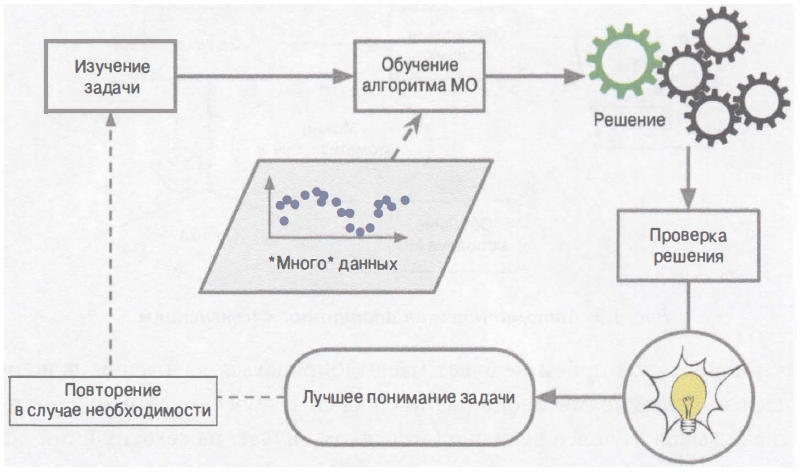
Рисунок «Машинное обучение может помочь учиться людям»
Типы систем машинноrо обучения
Существует так много разных типов систем машинного обучения, что их удобно сгруппировать в обширные категории на основе следующих признаков:
- обучаются ли они с человеческим контролем (обучение с учителем, обучение без учителя, частичное обучение (semisupervised learning) и обучение с подкреплением (Reinforcement Learning));
- могут ли они обучаться постепенно на лету (динамическое или пакетное обучение);
- работают ли они, просто сравнивая новые точки данных с известными точками данных, или взамен обнаруживают паттерны в обучающих данных и строят прогнозирующую модель подобно тому, как поступают ученые (обучение на основе образцов или на основе моделей).
Перечисленные критерии не являются взаимоисключающими; вы можете комбинировать их любым желаемым образом. Например, современный фильтр спама способен обучаться на лету, используя модель глубокой нейронной сети, которая обучена с применением примеров спам-сообщений и нормальных сообщений; это делает его динамической, основанной на моделях системой обучения с учителем. Давайте более подробно рассмотрим каждый из указанных выше критериев.
Обучение с учителем и без учителя
Системы МО могут быть классифицированы согласно объему и типу контроля, которым они подвергаются во время обучения. Есть четыре главных категории: обучение с учителем, обучение без учителя, частичное обучение и обучение с подкреплением. Обучение с учителем При обучении с учителем обучающие данные, поставляемые вами алгоритму, включают желательные решения, называемые метками (label).
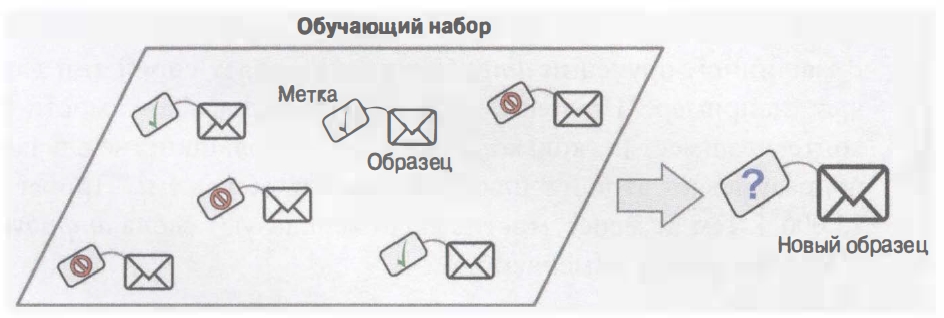
Рисунок «Помеченный обучающий набор для обучения с учителем (пример с классификацией спама)»
Типичной задачей обучения с учителем является классификация. Фильтр спама служит хорошим примером классификации: он обучается на многих примерах сообщений с их классом (спам или не спам), а потому должен знать, каким образом классифицировать новые сообщения. Другая типичная задача — прогнозирование целевого числового значения, такого как цена автомобиля, располагая набором характеристик или признаков (пробег, возраст, марка и т.д.), которые называются прогнозаторами (predictor). Задачу подобного рода именуют регрессией. Чтобы обучить систему, вам необходимо предоставить ей много примеров автомобилей, включая их прогнозаторы и метки (т.е. цены).
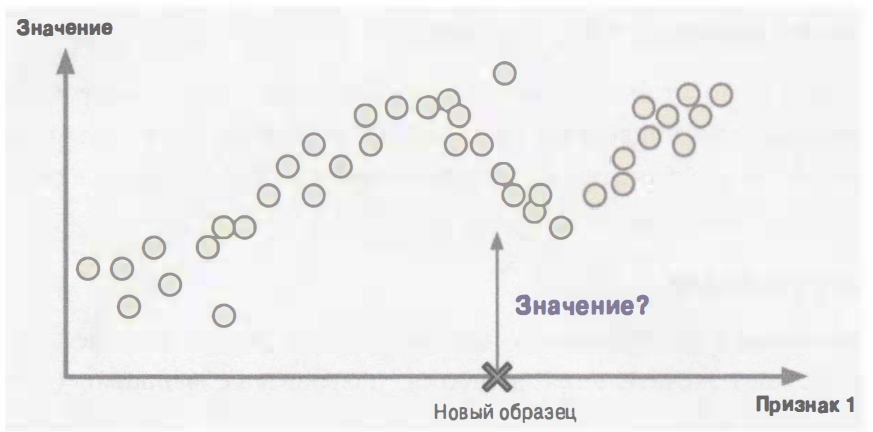
Рисунок «Регрессия»
В машинном обучении атрибут представляет собой тип данных (например, «Пробег»), тогда как признак в зависимости от контекста имеет несколько смыслов, но в большинстве случаев подразумевает атрибут плюс его значение (скажем, «Пробег = 15 ООО»). Тем не менее, многие люди используют слова атрибут и признак взаимозаменяемо. Обратите внимание, что некоторые алгоритмы регрессии могут применяться также для классификации и наоборот. Например, логистическая регрессия (logistic regressioп) обычно используется для классификации, т.к. она способна производить значение, которое соответствует вероятности принадлежности к заданному классу (скажем, спам с вероятностью 20%). Ниже перечислены некоторые из самых важных алгоритмов обучения с учителем:
- k ближайших соседей (k-nearest neighbors)
- линейная регрессия (linear regression)
- логистическая регрессия (logistic regression)
- метод опорных векторов (Support Vector Machine — SVM)
- деревья принятия решений (decision tree) и случайные леса (random forest)
- нейронные сети (neural network)
Обучение без учителя
При обучении без учителя, как вы могли догадаться, обучающие данные не помечены. Система пытается обучаться без учителя.
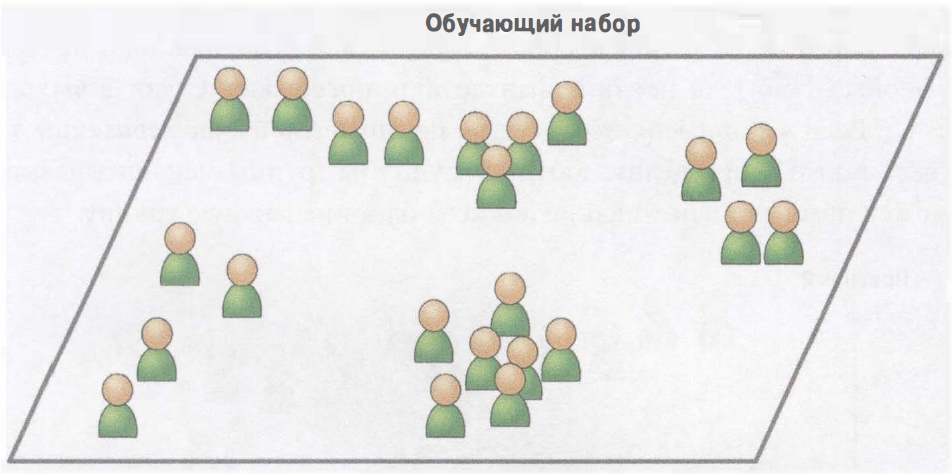
Рисунок «Непомеченный обучающий набор для обучения без учителя»
Далее приведен список наиболее важных алгоритмов обучения без учителя:
- Кластеризация
- k-средние (k-means)
о иерархический кластерный анализ (Hierarchical Cluster Analysis НСА) - максимизация ожиданий ( expectation maximization)
- k-средние (k-means)
- Визуализация и понижение размерности о анализ главных компонентов (Principal Component Analysis — РСА)
- ядерный анализ главных компонентов (kernel РСА)
- локальное линейное вложение (Locally-Linear Embedding — LLE)
- стохастическое вложение соседей с t-распределением (t-distributed Stochastic Neighbor Embedding — t-SNE)
- Обучение ассоциативным правилам ( association rule learning)
- Apriori
- Eclat
Например, предположим, что вы имеете много данных о посетителях своего блага. Вы можете запустить алгоритм кластеризации, чтобы попытаться выявить группы похожих посетителей. Алгоритму совершенно ни к чему сообщать, к какой группе принадлежит посетитель: он найдет такие связи без вашей помощи. Скажем, алгоритм мог бы заметить, что 40% посетителей — мужчины, которые любят комиксы и читают ваш благ вечерами, 20% — юные любители научной фантастики, посещающие благ в выходные дни, и т.д. Если вы применяете алгоритм иерархической кластеризации, тогда он может также подразделить каждую группу на группы меньших размеров. Это может помочь в нацеливании записей блага на каждую группу.

Рисунок «Кластеризация»
Алгоритмы визуализации тоже являются хорошими примерами алгоритмов обучения без учителя: вы обеспечиваете их большим объемом сложных и непомеченных данных, а они выводят двухмерное или трехмерное представление данных, которое легко вычерчивать. Такие алгоритмы стараются сохранить столько структуры, сколько могут (например, пытаются не допустить наложения при визуализации отдельных кластеров во входном пространстве), поэтому вы можете понять, как данные организованы, и возможно идентифицировать непредвиденные паттерны. Связанной задачей является понижение размерности, цель которой упростить данные без потери слишком многой информации. Один из способов предусматривает слияние нескольких связанных признаков в один. Например, пробег автомобиля может находиться в тесной связи с его возрастом, так что алгоритм понижения размерности объединит их в один признак, который представляет степень износа автомобиля. Это называется выделением признаков (featиre extraction).
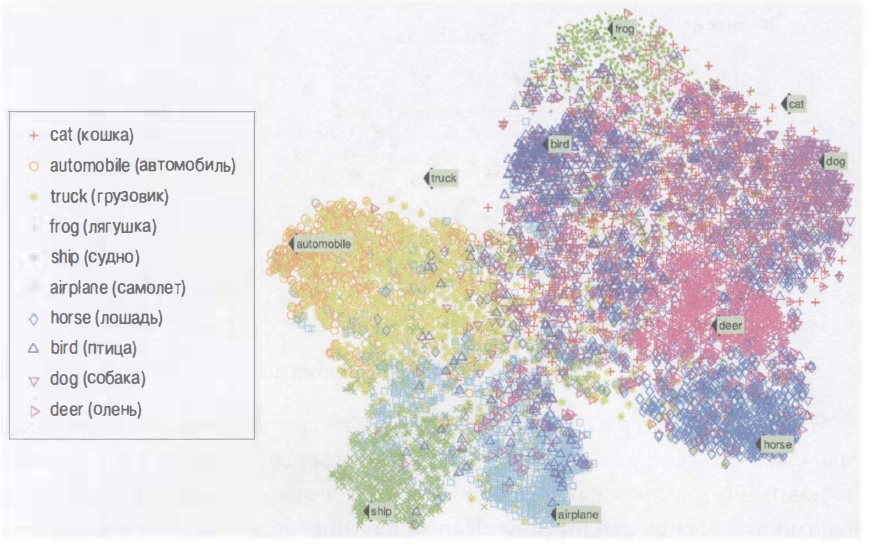
Рисунок «Пример визуализации t-SNE, выделяющей семантические кластеры»
Часто имеет смысл попытаться сократить размерность обучающих данных, используя алгоритм понижения размерности, до их передачи в другой алгоритм МО (такой как алгоритм обучения с учителем). В итоге другой алгоритм МО станет намного быстрее, данные будут занимать меньше места на диске и в памяти, а в ряде случаев он может также эффективнее выполняться.
Еще одной важной задачей обучения без учителя является обнаружение аномалий (anomaly detection) -например, выявление необычных транзакций на кредитных картах в целях предотвращения мошенничества, отлавливание производственных дефектов или автоматическое удаление выбросов из набора данных перед его передачей другому алгоритму обучения. Система обучалась на нормальных образцах, и когда она видит новый образец, то может сообщить, выглядит он как нормальный или вероятно представляет собой аномалию.

Рисунок «Обнаружение аномалий»
Наконец, в число распространенных задач входит обучение ассоциативным правилам (association rule learning), цель которого заключается в проникновении внутрь крупных объемов данных и обнаружении интересных зависимостей между атрибутами. Например, предположим, что вы владеете супермаркетом. Запуск ассоциативного правила на журналах продаж может выявить, что люди, покупающие соус для барбекю и картофельные чипсы, также склонны приобретать стейк. Таким образом, может возникнуть желание разместить указанные товары ближе друг к другу. Частичное обучение Некоторые алгоритмы способны работать с частично помеченными обучающими данными, в состав которых обычно входит много непомеченных данных и чуть-чуть помеченных. Процесс называется частичным обучением.

Рисунок «Частичное обучение»
Хорошими примерами могут быть некоторые службы для размещения фотографий наподобие Google Фото. После загрузки в такую службу ваших семейных фотографий она автоматически распознает, что одна и та же особа А появляется на фотографиях 1, 5 и 11, а другая особа В — на фотографиях 2, 5 и 7. Так действует часть алгоритма без учителя (кластеризация). Теперь системе нужно узнать у вас, кто эти люди. Всего одной метки на особу4 будет достаточно для того, чтобы служба смогла назвать всех на каждой фотографии, что полезно для поиска фотографий. Большинство алгоритмов частичного обучения являются комбинациями алгоритмов обучения без учителя и с учителем. Например, глубокие сети доверия (DBN) основаны на компонентах обучения без учителя, называемых ограниченными машинами Больцмана (RВМ), уложенными друг поверх друга. Машины RВМ обучаются последовательно способом без учителя, после чего целая система точно настраивается с применением приемов обучения с учителем.
Обучение с подкреплением
Обучение с подкреплением — совершенно другая вещь. Обучающая система, которая в данном контексте называется агентом, может наблюдать за средой, выбирать и выполнять действия, выдавая в ответ награды (или штрафы в форме отрицательных наград). Затем она должна самостоятельно узнать, в чем заключается наилучшая стратегия, называемая политикой, чтобы со временем получать наибольшую награду. Политика определяет, какое действие агент обязан выбирать, когда он находится в заданной ситуации. Например, многие роботы реализуют алгоритмы обучения с подкреплением, чтобы учиться ходить. Также хорошим примером обучения с подкреплением является программа AlphaGo, разработанная DeepMind: она широко освещалась в прессе в мае 2017 года, когда выиграла в го у чемпиона мира Кэ Цзе. Программа обучилась своей выигрышной политике благодаря анализу миллионов игр и затем многократной игре против самой себя. Следует отметить, что во время игр с чемпионом обучение было отключено; программа AlphaGo просто применяла политику, которой научилась ранее.

Рисунок «Обучение с подкреплением»
Пакетное и динамическое обучение
Еще один критерий, используемый для классификации систем МО, связан с тем, может ли система обучаться постепенно на основе потока входящих данных. Пакетное обучение При пакетном обучении система неспособна обучаться постепенно: она должна учиться с применением всех доступных данных. В общем случае процесс будет требовать много времени и вычислительных ресурсов, поэтому обычно он проходит автономно. Сначала система обучается, а затем помещается в производственную среду и функционирует без дальнейшего обучения; она просто применяет то, что ранее узнала. Это называется автономным обучением (offline learning). Если вы хотите, чтобы система пакетного обучения узнала о новых данных (вроде нового типа спама), тогда понадобится обучить новую версию системы с нуля на полном наборе данных (не только на новых, но также и на старых данных), затем остановить старую систему и заменить ее новой. К счастью, весь процесс обучения, оценки и запуска системы МО можно довольно легко автоматизировать, так что даже система пакетного обучения будет способной адаптироваться к изменениям. Просто обновляйте данные и обучайте новую версию системы с нуля настолько часто, насколько требуется.
Такое решение просто и зачастую прекрасно работает, но обучение с использованием полного набора данных может занять много часов, поэтому вы обычно будете обучать новую систему только каждые 24 часа или даже раз в неделю. Если ваша система нуждается в адаптации к быстро меняющимся данным (скажем, для прогнозирования курса акций), то понадобится более реактивное решение. Кроме того, обучение на полном наборе данных требует много вычислительных ресурсов (процессорного времени, памяти, дискового пространства, дискового ввода-вывода, сетевого ввода-вывода и т.д.). При наличии большого объема данных и автоматизации системы для обучения с нуля ежедневно все закончится тем, что придется тратить много денег. Если объем данных громаден, то применение алгоритма пакетного обучения может даже оказаться невозможным. Наконец, если ваша система должна быть способной обучаться автономно, и она располагает ограниченными ресурсами (например, приложение смартфона или марсоход), тогда доставка крупных объемов обучающих данных и расходование многочисленных ресурсов для ежедневного обучения в течение часов станет непреодолимой проблемой. Но во всех упомянутых случаях есть лучший вариант — использование алгоритмов, которые допускают постепенное обучение. Динамическое обучение При динамическом обучении вы обучаете систему постепенно за счет последовательного предоставления ей образцов данных либо по отдельности, либо небольшими группами, называемыми мини-пакетами. Каждый шаг обучения является быстрым и недорогим, так что система может узнавать о новых данных на лету по мере их поступления. Динамическое обучение отлично подходит для систем, которые получают данные в виде непрерывного потока (скажем, курс акций) и должны адаптироваться к изменениям быстро или самостоятельно. Вдобавок динамическое обучение будет хорошим вариантом в случае ограниченных вычислительных ресурсов: после того, как система динамического обучения узнала о новых образцах данных, она в них больше не нуждается, а потому может их отбросить (если только вы не хотите иметь возможность производить откат к предыдущему состоянию и «воспроизведение» данных). В итоге можно сберечь громадный объем пространства.

Рисунок «Динамическое обучение
Алгоритмы динамического обучения также могут применяться для обучения систем на гигантских наборах данных, которые не умещаются в основную память одной машины (прием называется внешним обучением ( oиtof-core learning)). Алгоритм загружает часть данных, выполняет шаг обучения на этих данных и повторяет процесс до тех пор, пока не пройдет все данные.

Рисунок «Использование динамического обучения для обработки гигантских наборов данных»
Весь этот процесс обычно выполняется автономно ( т.е. не на действующей системе), так что название «динамическое обучение» может сбивать с толку. Думайте о нем как о постепенном обучении (incremental learning).
Важный параметр систем динамического обучения касается того, насколько быстро они должны адаптироваться к меняющимся данным: он называется скоростью обучения (learniпg rate). Если вы установите высокую скорость обучения, тогда ваша система будет быстро адаптироваться к новым данным, но также быть склонной скоро забывать старые данные (вряд ли кого устроит фильтр спама, маркирующий только самые последние виды спама, которые ему были показаны). И наоборот, если вы установите низкую скорость обучения, то система станет обладать большей инертностью; т.е. она будет обучаться медленнее, но также окажется менее чувствительной к шуму в новых данных или к последовательностям нерепрезентативных точек данных. Крупная проблема с динамическим обучением связана с тем, что в случае передачи в систему неправильных данных ее производительность будет понемногу снижаться. Если речь идет о действующей системе, тогда ваши клиенты заметят такое снижение. Например, неправильные данные могли бы поступать из некорректно функционирующего датчика в роботе либо от кого-то, кто заваливает спамом поисковый механизм в попытках повышения рейтинга в результатах поиска. Чтобы сократить этот риск, вам необходимо тщательно следить за системой и, обнаружив уменьшение производительности, сразу же отключать обучение (и возможно возвратиться в предыдущее рабочее состояние). Может также понадобиться отслеживать входные данные и реагировать на аномальные данные (скажем, с применением алгоритма обнаружения аномалий).